Sitecore Search can fix your Legacy API


We try to build our websites based on a modern technology stack. But every now and then, we are asked to integrate an API that returns a 5MB junk of XML into our platform. If it's not just me this sends shivers down the spine, you might want to keep reading.
The Scenario
Let's imagine we are an international company with two different recruitment platforms to manage open job positions. We want to merge the jobs into a unified list and integrate them into the website. The recruitement platforms offer an API, but the responses are slow and return massive XML documents.
Use Sitecore Search as an API Gateway
Instead of integrating the API's directly in the frontend application, we can let Sitecore Search process the API responses and add them to the search index. We can then use the Search API to access all jobs through a unified API, even if the two source systems return a different XML structure. With this approach, we don't have to implement and maintain the logic of how to merge and sort multiple responses in the frontend application. As an additional benefit, you get to use the full power of Sitecore Search when it comes to searching your data or boosting high priority job positions.
This blog post assumes you have a basic understanding of Sitecore Search concepts. If you are new to Sitecore Search, consider reading "Your first Sitecore Search Crawler" first.

How to index an XML API
For every API we want to index, we define a new source in Sitecore Search with a Web Crawler (Advanced) connector. In our scenario, this would be two sources.

Then, we need to define a trigger as a starting point for the crawler.
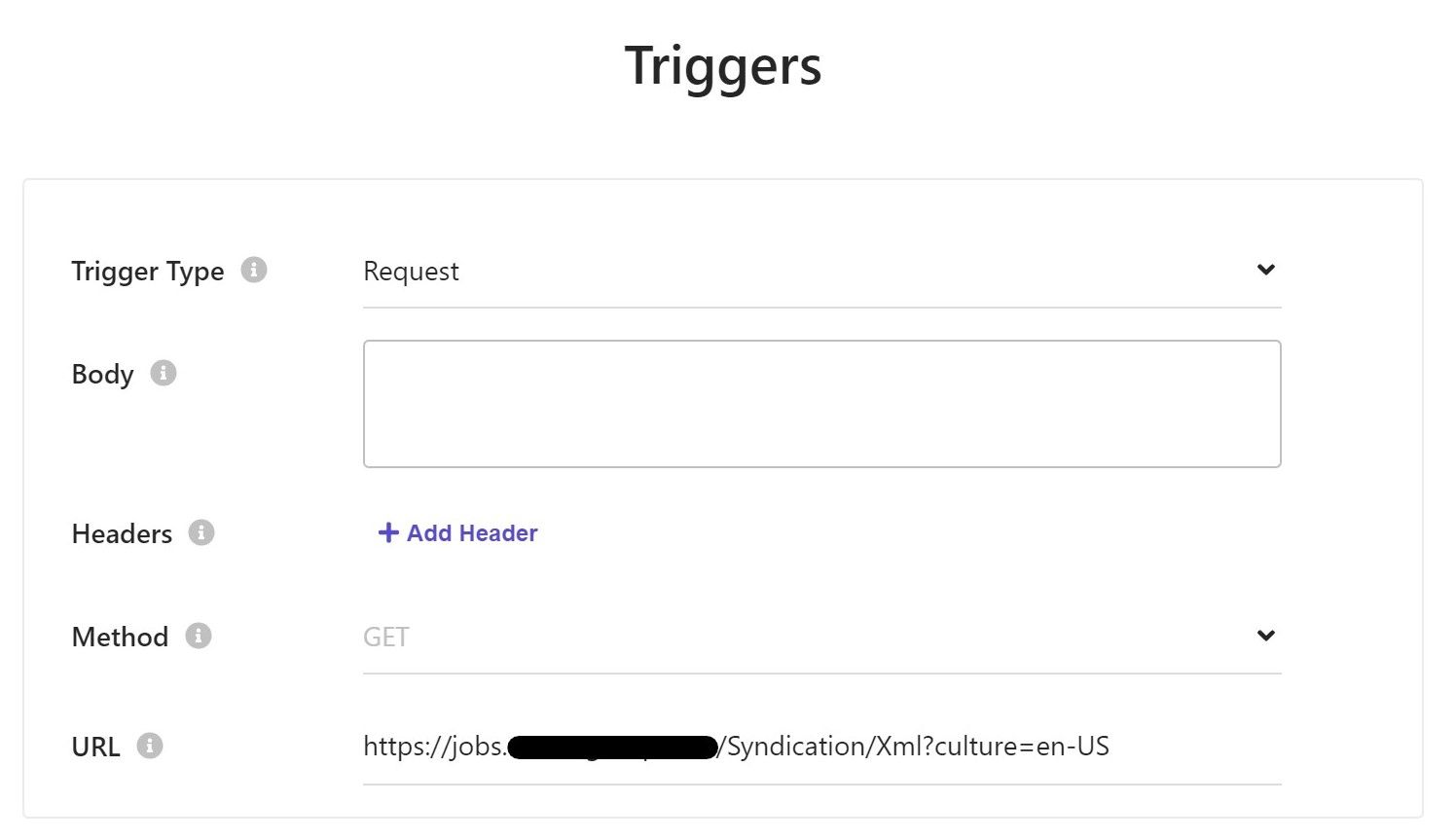
Triggers for public endpoints
You can use the Request trigger type, If you have a public endpoint, or one that is only protected by a request header.
Triggers for Basic Auth protected endpoints
If you have an endpoint that is behind a basic auth, you can use a JavaScript trigger type JS with the following trigger source.
function extract() {
return [
{
url: "YOUR_API_ENDPOINT_HERE",
headers: {
Authorization: ["Basic YOUR_AUTH_TOKEN_HERE"],
},
},
];
}
Add jobs to the Search Index
To add the the jobs, we need to implement a document extractor of type JS with a tagger to read the data from the response. The tagger could look similar to this simplified version.
function extract(request, response) {
var $ = response.body;
var jobs = $('feed').first().children('entry');
var out = [];
for (var i = 0; i < jobs.length; i++) {
var job = jobs[i];
var reqId = $(job).children('content').children('m\\:properties').find('d\\:jobReqId').text();
var title = $(job)
.find(
"link[rel='http://schemas.microsoft.com/ado/2007/08/dataservices/related/jobReqLocale']"
)
.find('d\\:externalTitle')
.text();
var description = $(job)
.find(
"link[rel='http://schemas.microsoft.com/ado/2007/08/dataservices/related/jobReqLocale']"
)
.find('d\\:externalJobDescription')
.text();
out.push({
id: reqId,
type: 'Job',
name: title,
job_name: title,
job_description: description,
job_number: reqId,
url: 'https://legacy.recruitmentportal.com/joblistings?jobId=' + reqId
});
}
return out;
}Whenever you return multiple objects from a tagger, you need to explicitely define a unique id. In our example, we use the job ID from the source system.
After you publish and run the crawler, you will have all job positions in the index and you can access them through the Sitecore Search API.
API Resilience
Integrating your APIs through Sitecore Search allows you to decouple the website from your original data sources. This means that if one of your data sources goes down, the index job will fail, but it will not affect your data. This can improve the overall resilience of your platform. While the data might get outdated over time, the Sitecore Search API is still available.
Summary
In this blog post, we discussed how to use Sitecore Search as an API gateway to integrate multiple source systems and aggregate their data. This approach makes it easy to handle performance concerns, as the crawlers run as jobs in the background. It also makes it easy to add new source systems without having to make changes to the frontend application.



