Improve your Sitecore Search Development Experience


What started out as a small piece of code to extract some metadata fields from your website markup is slowly growing in complexity. Testing, maintaining and extending your document extractor code is getting tougher. There is a very handy tool to change your development experience and speed up your work.
The downside of running a Search Crawler
Whenever you update the code in the document extractor of one of your Sitecore Search sources, you can publish the change and queue a job to recrawl your content. It usually takes a few minutes for a job to start running. It can become quite frustrating to wait 6 minutes only to see that you have a syntax error in your code.
Start using the Cheerio Playground
ScrapeNinja offers a free online tool to write Cheerio queries and debug them in your browser. You can find the Cheerio Sandbox here: https://scrapeninja.net/cheerio-sandbox/basic


Provide the website markup
As a first step, navigate to an example page of your website you want to crawl and copy the markup into the sample data field. The easiest way to access the markup is to use the View page source option from the right click menu. To reference an earlier blog post about Your first Sitecore Search Crawler, we will use the following markup.
<html>
<head>
<title>Diversity, Equity and Inclusion</title>
<meta name="description" content="Diversity, equality and inclusion allow us to open our minds to a variety of approaches and viewpoints and to tackle the challenges of the future." />
</head>
<body>
<div id="main"></div>
</body>
</html>Provide the document extractor code
Copy and paste the body of your document extractor code. Please be aware that the first two lines between your code and the code that the Cheerio Sandbox expects are slightly different.
function extract(request, response) {
$ = response.body;
//...
}Sitecore Search document extractor code
function extract(input, cheerio) {
let $ = cheerio.load(input);
//...
}Cheerio Sandbox code
In our example, we are using the the document extractor code from the previously mentioned blog post.
// define function which accepts body and cheerio as args
function extract(input, cheerio) {
// return object with extracted values
let $ = cheerio.load(input);
var pageContentType = $('meta[name="content_type"]').attr("content") || "Content";
var title =
$("h1.intro__title").text() ||
$('meta[property="og:title"]').attr("content") ||
$("title").text();
var description =
$('meta[name="description"]').attr("content") ||
$('meta[property="og:description"]').attr("content") ||
$("div.intro__content").find("p").text();
return {
type: pageContentType,
name: title,
description: description,
};
}
Run the extractor
Once you provided both the sample data and the extractor code, you click the Run extractor button to see the result.
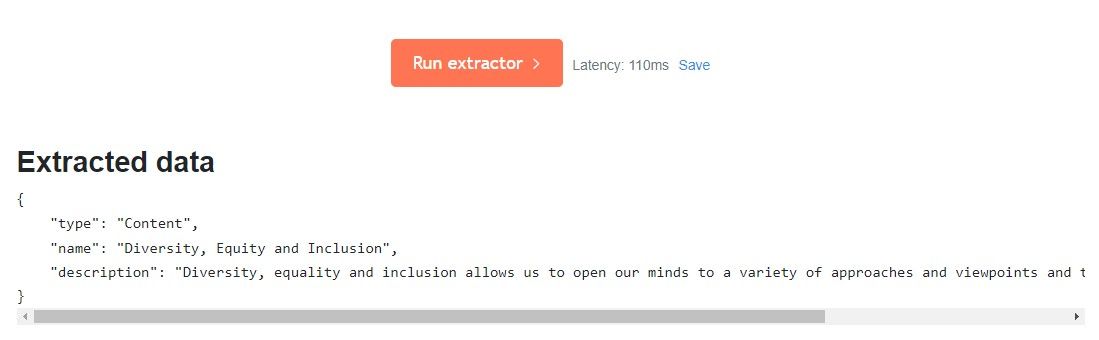
If the extracted data matches your expectations, copy the code back to Sitecore Search. Don't forget to change the first two lines back to what the crawler expects.
Debugging Tip
As there is no special debugging environment, adding console.log statements can help you understand what is happening in your code. Wrapping it in small helper function might help you add and remove the console output.
function extract(input, cheerio) {
let $ = cheerio.load(input);
function l(line) {
console.log(line);
}
//...
var introContent = $("div.intro__content").find("p").text();
l(introContent);
//...
}Console log in a simple wrapper function
The log output will be displayed under the extracted data.
Crawling an XML source
In my previous blog post about how Sitecore Search can fix your Legacy API, we indexed an XML source.

You can configure Cheerio to load the document in XML mode.
function extract(request, response) {
let $ = cheerio.load(input, {
xml: true,
});
//...
}Helpful Snippets
If you want too find the first header in a specifc section of your website:
var contentIntro = $('div.intro').find('h2, h3, h4').first().text();If you want to have a static fallback value:
var pageContentType = $('meta[name="content_type"]').attr('content') || 'Content';If you want to add a breadcrumb as an array of strings:
var breadcrumbs = [];
$breadcrumbItems = $('#content').find('li.breadcrumb__item');
$breadcrumbItems.each((i, elem) => {
var breadcrumbItem = $(elem).find('a').text();
if (breadcrumbItem) {
breadcrumbs.push(breadcrumbItem);
}
});If you want to add a relative date facet:
function addDays(date, days) {
const copy = new Date(Number(date));
copy.setDate(date.getDate() + days);
return copy;
}
eventStartDate = $('meta[name="event_start_date"]').attr('content');
var startDate = new Date(eventStartDate);
var now = new Date();
if (eventStartDate && !isNaN(startDate) && now < startDate) {
if (startDate < addDays(now, 30)) {
eventDateFacet = 'Next 30 days';
} else if (startDate < addDays(now, 90)) {
eventDateFacet = 'Next 90 days';
} else if (startDate < addDays(now, 365)) {
eventDateFacet = 'Next 12 months';
}
}If you want to use the current url as an ID:
return {
id: url.replace(/[^a-zA-Z\d_-]/g, '_'),
};You might find more helpful tips in the Cheerio Cheatsheet.
Considerations and outlook
Sitecore Search currently does not offer any kind of versioning of the document extractor code. We established a good practice of adding the code to the version control system of the rest of the code base. In the future, Sitecore Search may add a native versioning system or provide an option to automate the process through a CLI.



